お問合せ
Predictive Maintenance of Conveyor Belts with Digital Twins
An interview with expert Jörg Arloth

Profitability is one of the fundamental goals in the development and operation of complex machines and systems. New, data-based methods (big data, machine learning) now enable smart services (e.g. predictive maintenance) and help meet this requirement by avoiding unplanned downtimes and reducing operating and maintenance costs. I spoke to my ESI colleague Jörg Arloth, Account Manager Mining, and asked about the current state of the art.
Q. Big data and machine learning are trending in digitization in all industries. Looking at manufacturers and operators of mining machines, where do you currently see most of the starting points?
Jörg. A current challenge is bringing together data-based methods and expert knowledge from real-life practice and assigning existing measurement data to the causes of defects or wear and transfer them to other systems. Only then can the development of data-based pattern recognition be crowned with success. The physical system simulation, combined with proven workflows, offers a solution that facilitates practical application and supports communication between experts from various fields. Models can be created automatically; desired error behavior can be integrated in a targeted manner and a wide variety of virtual operating data can be generated.
Q. In your lecture at the belt conveyor conference, you outlined the workflow of an SRA-based condition analysis of belt conveyors to support predictive maintenance strategies. The starting point and basis of this concept is a digital twin using the example of a belt conveyor. How exactly is that supposed to work?
Jörg. If, as with belt conveyors, the system model can be generalized, it can be created automatically. With system simulation, the generalization is achieved by applying the belt conveyor library in ESI SimulationX. From the included elements, a script-based model generator creates the system model. I briefly sketched the workflow from the library to the digital twin:
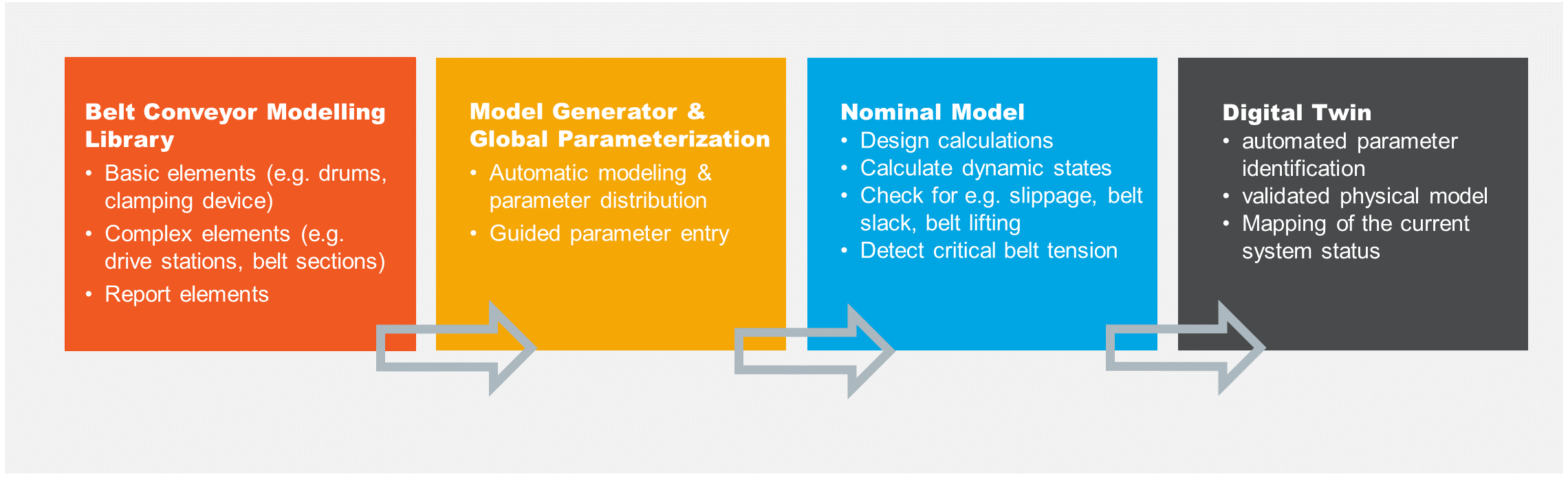
The resulting simulation model describes the structure of the system and is parameterized, centrally, in a data container. The picture on the left shows a simulation model of a belt conveyor that is then loaded with a standardized mass flow that was generated from real measurement data and thus represents a real loading process over time (load).
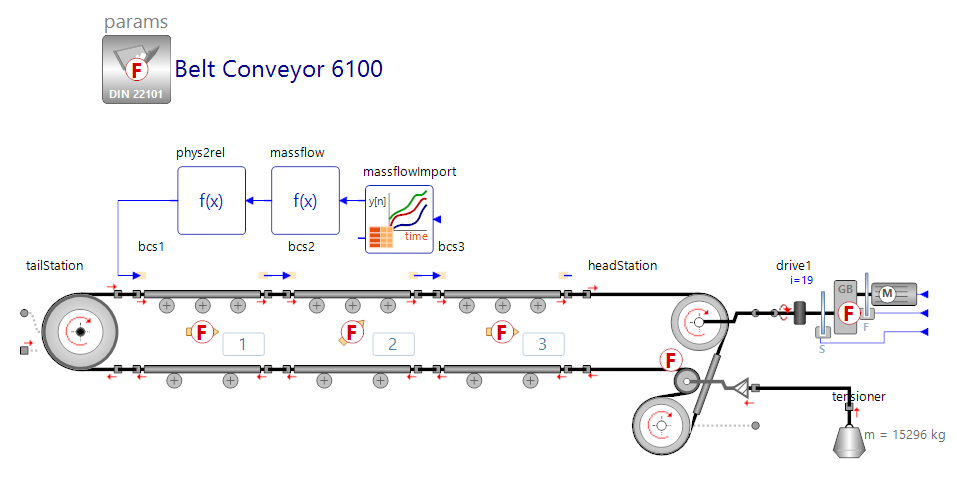
Q. A very important criterion for the quality and reliability of the created digital twin is data consistency. What can you say about the data measured in real-life scenarios versus the one you obtained using simulation?
Jörg. That is a very important aspect. To validate our simulation model, we took the data from a conveyor system that was in operation. If you compare the real measured values with the simulation data in the picture on the right, you can see a sufficiently large correspondence between the simulation and measurement data. The quality criterion met has been met.
Q. Let's move on to another important point - the SRA analysis. What exactly is behind the new technology?
Jörg. In the image below, I show you an example of our SRA analysis approach for the belt conveyor application where you can see how new ideas can be developed, tested and evaluated in the simulation model. This is key for ideas to be checked completely virtually, upfront, in development instead of inventing complex and unrealistic measurement strategies. As a side effect, such a digital approach may even generate the need for new measurement technology.

Q. So, looking at performance in real-life operations, you have collected a multitude of possible errors and put them together in a library?
Jörg: Exactly. The fault model we generated is very much what you see here. All model elements with parametric errors are marked with a red "F" and are part of an automatically generated error library.
You can clearly see the structural view of the belt conveyor model with implemented parametric errors. This includes errors that can be assigned directly, such as caking on the drums, but also complex errors that are characterized by a change in the coefficient of friction. This can be done globally in order to mark general aging and wear. But it can also be done locally in order to map steady-state influences or effects originating from the moving belt.
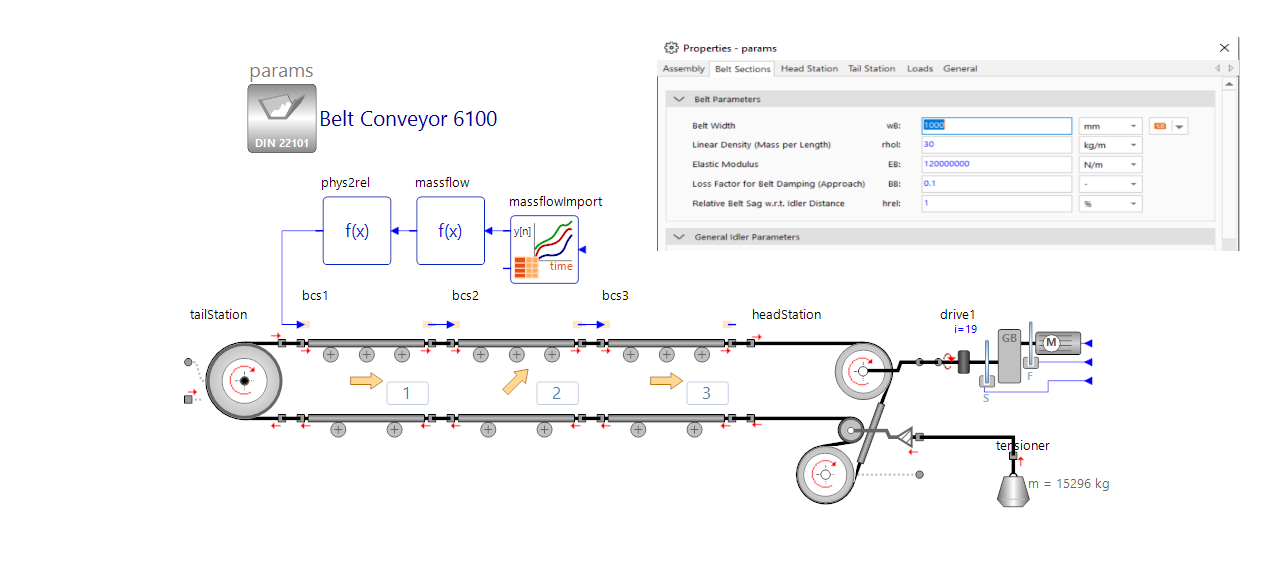
In addition to the usual measurement signals, such as speed (motor, rotating drums) and drive torque, the current total load is measured using virtual sensors and the belt tension forces of the individual model sections in this test. This is to clarify the question of whether such different failure effects could be detected and identified, even if several failures happen to occur at the same time.
For example, a broad range of features are continuously monitored, like the maximum belt tension on the drive drum, the normed power and the normed drive torque per current load as well as the normed belt tensile forces based on the nominal behavior (based on a nominal model). This means that engineers could calculate a large number of variants (defect size and combination) and their impact on the conveyor’s performance.
Q. Machine learning algorithms are used to analyze the effects of errors on the model. How exactly does this contribute to a predictive maintenance strategy?
Jörg. Correct. We use machine learning algorithms to evaluate the results of the variant calculation. The quality of decision trees, for example, shows clearly the dependencies between the generated features and the errors and how precisely threshold values can be defined. While caking can be detected very easily using the quotient of different engine and drum speeds, it is much more difficult to assign aging effects. Due to the different loading conditions during operation, very robust threshold values must be selected.
To illustrate this better, let's look back at the image above where you see the standardized belt tension forces of the individual sections. The starting point of the idea is that the belt tension forces can be measured for each section in the model (here BCS1, BCS2, BCS3, HeadStation). The belt tension forces under consideration are localized running up onto the respective belt section. Without developing or installing appropriate sensors, engineers know what conclusions they shall draw from these signals. For this purpose, the belt tension forces are normalized using the calculated belt tension forces of a nominal model.
Q. That was a lot of theoretical and technical facts. In conclusion, how would you summarize the topic for our speed readers?
Jörg. Intelligent (smart) services and the machine learning algorithms used for them require the provision of sufficient quantities of operational data. This already applies to the preparation of service strategies for new systems that do not have any field data at this point in time. Data-based analyses of systems, as described in the article, are an effective means of generating such realistic amounts of data. The inclusion and evaluation of sources of error and their interactions represent, on the one hand, an opportunity to include the experience of operating and service personnel and make them usable on a broad basis, and, on the other hand, to protect the system from sensor overloading. The SRA-based workflow shown supports data acquisition and the development of new solutions, both for increasing system availability and for predictive maintenance strategies.
For more insight on delivering safer, cleaner, and more productive machinery with Virtual Prototyping visit our dedicated Heavy Machinery page.
Do you want to leverage discussions on key technologies to face not only challenges related to product design, but also product manufacturing, product assembly, and product operations? Watch our ESI LIVE Heavy Machinery

Author
Peter Larsson
Industry Channel Director for Heavy Industry
Peter Larsson joined ESI in 2016, bringing with him his expertise in industry strategy, business development and product management. For more than 20 years, Peter has been managing B2B software solutions targeting major enterprise customers in manufacturing industries such as automotive and transportation, aerospace and heavy industry.
Since the late ’90s, he has been actively involved in the areas of design engineering, manufacturing engineering, visualization & virtual reality offerings, with a focus on helping customers address key digitalization challenges to efficiently deliver high-performance, quality products, on time, with a key focus on health and safety considerations for both products and processes.
Peter holds a Master of Science in Computing Science from Gothenburg University, Sweden, and Business Management from IHM School of Business.
Category: Digital Transformation, Heavy Machinery